
-
客户端发起IO请求:应用程序运行在Ceph的客户端节点上,当应用程序需要读取或写入数据时,会发起IO请求。
-
客户端与Metadata Server(MDS)交互:如果是文件系统(如CephFS)的IO请求,客户端会与MDS交互以获取文件的元数据信息,如文件的位置和权限等。
-
客户端与CRUSH Map交互:CRUSH(Controlled Replication Under Scalable Hashing)是Ceph中用于数据分布和故障域管理的算法。客户端会通过与CRUSH Map交互,确定数据所在的OSD(对象存储设备)和PG(Placement Group)。
-
客户端与OSD交互:客户端与被确定的OSD节点建立连接,并发送IO请求。如果是读取请求,OSD会返回请求的数据;如果是写入请求,OSD会将数据写入存储设备,并返回确认信息。
-
数据复制和条带化:根据Ceph的配置和策略,数据可能会进行复制和条带化。数据复制可以提高数据的冗余和可用性,而条带化可以实现数据的并行读取和写入,提高IO性能。
-
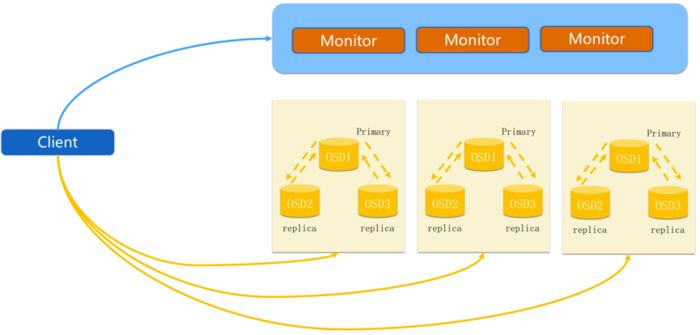

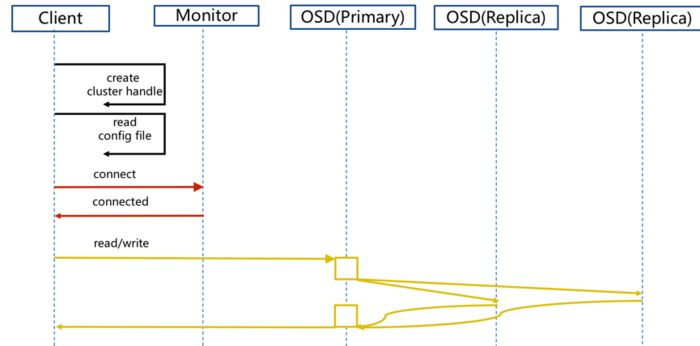
以上是简化的Ceph IO流程示意图,实际的流程可能会因Ceph的配置和部署方式而有所不同。在Ceph中,数据的发布是指数据已经成功写入并复制到多个OSD上,确保数据的持久性和可用性。
如果有新加入的OSD1取代了原有的OSD4成为Primary OSD,由于OSD1上未创建PG,不存在数据,那么PG上的IO无法进行,如何工作呢?
当新加入的OSD(OSD1)取代了原有的Primary OSD(OSD4),并且在OSD1上没有创建对应的PG(Placement Group),会导致PG上的IO无法进行。在这种情况下,Ceph会进行以下工作:
-
PG处于不可用状态:当Primary OSD(OSD4)被替换时,PG会被标记为不可用状态。这意味着PG上的IO请求无法被处理,因为没有可用的Primary OSD来处理这些请求。
-
PG重新平衡:Ceph会自动触发PG的重新平衡过程。在重新平衡过程中,Ceph会尝试将PG中的数据重新分布到其他可用的OSD上,以确保数据的可用性和冗余性。
-
选择新的Primary OSD:在PG重新平衡的过程中,Ceph会选择一个新的Primary OSD来接管PG的处理。通常,Ceph会选择具有最新副本的OSD作为新的Primary OSD。
-
数据迁移:一旦新的Primary OSD(OSD1)被选定,Ceph会开始将PG中的数据从其他OSD迁移到OSD1上。这个过程称为数据再平衡,它确保PG中的数据在集群中的多个OSD之间得到恢复和复制。
-
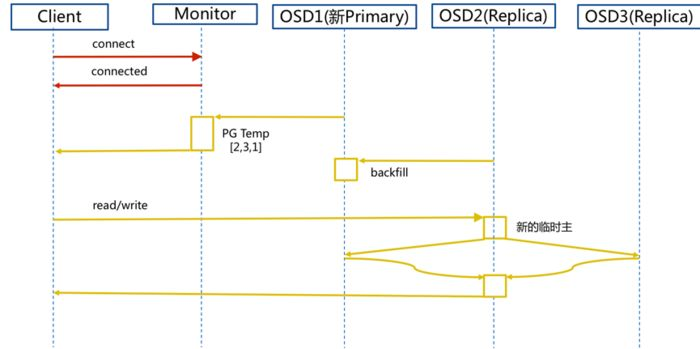
上图为工作简要流程图,PG的重新平衡和数据迁移过程可能需要一定的时间,具体取决于集群的规模等因素。在此期间,PG上的IO请求可能会受到一定的延迟或影响。但是,Ceph会尽力确保数据的可用性和一致性,并在后面的操作中恢复正常的IO处理能力。
原创文章,作者:geeklinux.cn,如若转载,请注明出处:https://www.geeklinux.cn/cloud-native/ceph/1273.html