
Ceph的存储过程包括数据的写入和读取。写入过程涉及数据分片、数据编码、数据复制和数据分发等步骤。读取过程涉及数据定位、数据恢复和数据传输等步骤。
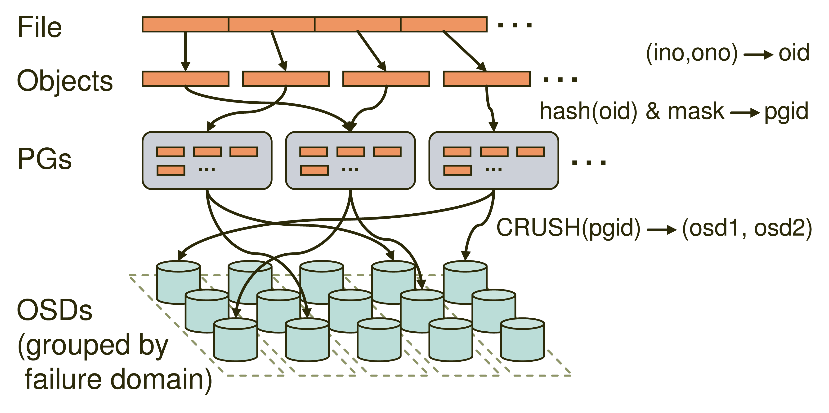

1.File—-此处的File就是用户要存储或者访问的文件。对于一个基于Ceph开发的对象存储应用而言,这个File也就是对应于应用中的对象,也就是用户直接操作的对象
2.Objects—-此处的Objects是RADOS所看到的对象。Object与上面提到的File的区别是,Object的最大Size由RADOS限定(通常为2MB或4MB),以便实现底层存储的组织管理。因此,当上层应用向RADOS存储size很大的file时,需要将file切分统一大小的一系列object(最后一个的大小可以不同)进行存储。
3.PG (Placement Group)—-顾名思义,PG的用途是对object的存储进行组织和位置映射。一个PG负责若干个object(可以为数前个甚至更多),但一个object只能被映射到一个PG中,即,PG和object之间是一对多映射关系。同时,一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG,即,PG和OSD之间是多对多映射关系。如果用于生产环境,OSD至少为3.一个OSD上的PG则可达到数百个。事实上,PG数量的设置牵扯到数据分布的均衡性问题。
4.OSD —-即object storage device 需要说明的是OSD的数量事实上也关系到系统的数据分布均衡性,因此数量不能太少。
基于上述定义,Ceph中的寻址至少要经历下面三次映射
1️⃣ CRUSH映射(CRUSH Mapping)
CRUSH(Controlled Replication Under Scalable Hashing)是Ceph中用于数据分布和数据位置计算的算法。在CRUSH映射中,客户端通过CRUSH算法将对象的名称映射到具体的OSD。CRUSH算法基于集群的拓扑结构和权重信息,以一致性哈希的方式计算对象的存储位置,从而实现数据的均衡分布和负载均衡。
CRUSH映射算法公式
hash = hash_func(object_name)
bucket = root_bucket
while bucket is not osd:
for item in bucket.items:
if item.type == bucket_type and hash < item.hash:
bucket = item
break
else:
bucket = bucket.items[-1]
osd = bucket.items[0].id
2️⃣OSD映射(OSD Mapping)
在CRUSH映射确定了对象所在的OSD之后,客户端需要获取最新的OSD映射信息,以确定对象所在的具体OSD的位置。客户端通过与Monitor交互获取cluster map,其中包含了OSD的状态和位置信息。通过解析cluster map,客户端可以确定对象所在的OSD。
OSD映射算法公式
osd = find_osd(object_name)
3️⃣RADOS映射(RADOS Mapping)
一旦客户端确定了对象所在的OSD,它就可以直接与该OSD进行通信,进行数据的读取、写入或其他操作。客户端通过与OSD进行交互,将对象的名称映射到具体的数据块,从而实现对数据的访问
RADOS映射算法公式
data_block = osd.read(object_name)
在Ceph中进行数据寻址的过程通常需要经历CRUSH映射、OSD映射和RADOS映射这三次映射。CRUSH映射将对象的名称映射到OSD,OSD映射确定对象所在的具体OSD的位置,而RADOS映射将对象的名称映射到具体的数据块,实现对数据的访问。这些映射过程帮助客户端定位和访问Ceph存储集群中的数据,上面提到的算法公式描述了在Ceph中进行数据寻址的过程。首先,CRUSH映射算法根据对象的名称和哈希值,逐级遍历桶(bucket)来确定最终的OSD。然后,OSD映射算法通过获取最新的cluster map,直接找到对象所在的OSD。最后,RADOS映射算法使用对象的名称与所在的OSD进行交互,进行数据的读取或其他操作。
可能会有的疑问:为什么需要同时设计出第二次和第三次映射?难道不重复吗?
在Ceph中,第二次和第三次映射并不是为了重复映射,而是为了实现不同的功能和目的。
第一次映射是指CRUSH算法的映射过程,它将对象映射到特定的OSD。CRUSH算法使用哈希函数和故障域的层次结构来决定对象在集群中的位置,以实现负载均衡和数据冗余。
第二次映射是指OSD映射,它是根据对象的名称直接找到对象所在的OSD。这个映射过程可以看作是CRUSH算法的简化版本,它可以更快地找到对象所在的OSD,而无需进行完整的CRUSH计算。
第三次映射是指RADOS映射,它是客户端与OSD之间的交互过程。客户端使用对象的名称和OSD进行通信,进行读取、写入、删除等操作。这个映射过程是为了实现客户端与存储集群之间的数据交互。
这三次映射的设计是为了实现不同的目的和功能。CRUSH算法提供了高度可扩展和灵活的数据分布策略,确保数据在集群中的均衡分布和冗余备份。OSD映射提供了快速定位对象所在OSD的能力,以提高数据访问的效率。RADOS映射则是实现客户端与存储集群之间的数据交互的关键。
原创文章,作者:geeklinux.cn,如若转载,请注明出处:https://www.geeklinux.cn/cloud-native/ceph/736.html