
什么是 Ollama ?
随着语言模型的日益普及和功能的提高,能够在本地运行它们为在本地开发和研究这些模型提供了显著的优势。Ollama 是一个开源命令行工具,可用于在计算机上运行、创建和共享大型语言模型。
Ollama 允许您运行大型语言模型,例如 Llama 2 和 Code Llama,而无需任何注册或等待列表。它不仅支持现有模型,而且还提供了自定义和创建自己的模型的灵活性。您可以在 Ollama 库中找到支持的模型列表。
您可以轻松地从 Ollama 库导入模型并开始使用这些模型,而无需安装任何依赖项。
项目地址:https://github.com/ollama/ollama
Ollama是如何工作的?
如果您熟悉 Docker,Ollama 的工作方式其实与 Docker 类似,它提供了一个环境,任何人都可以在其中提取、测试和修改机器学习模型,类似于使用 Docker 映像。
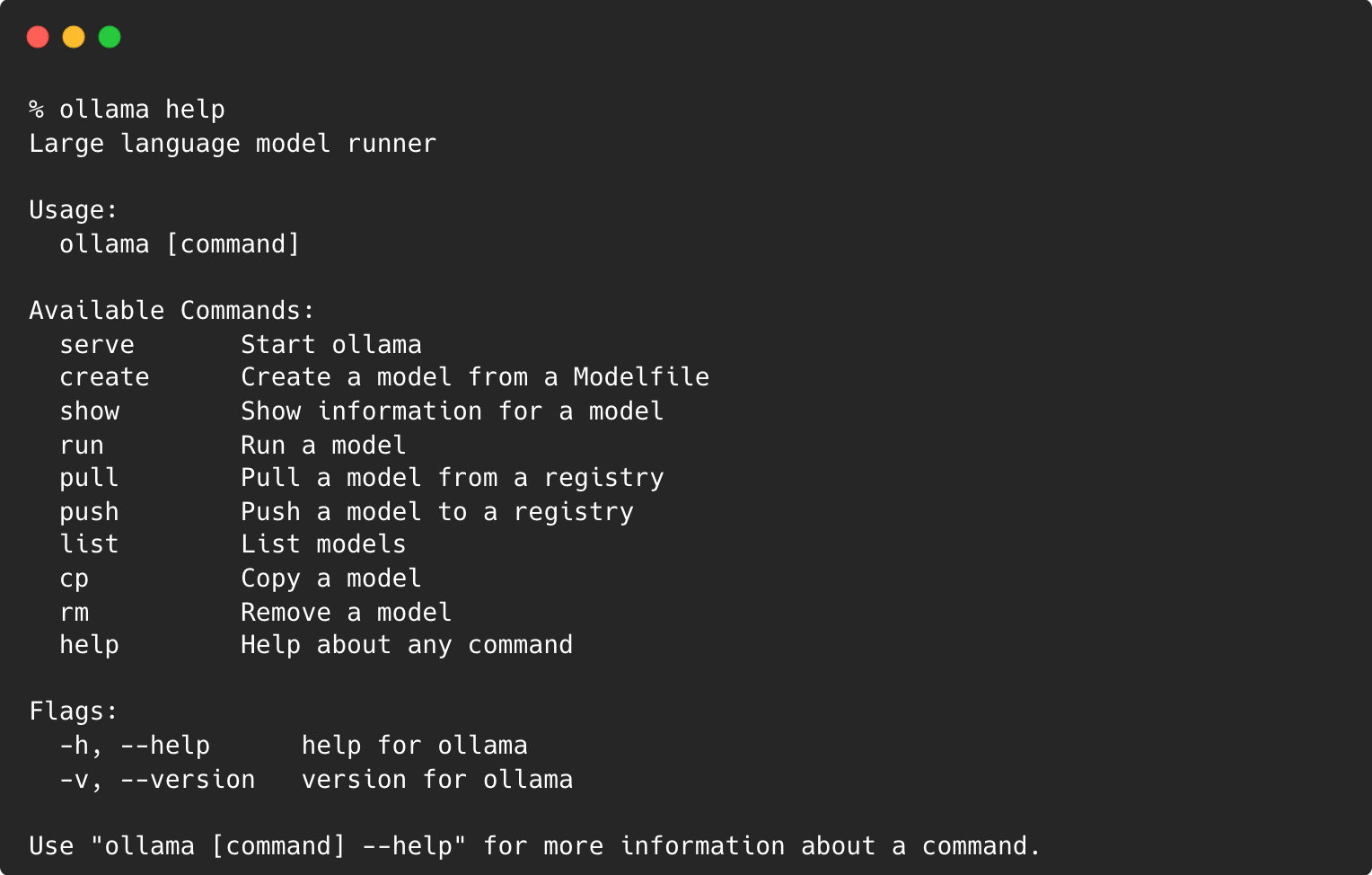

- 拉取模型 – 与 Docker 的拉取命令非常相似,Ollama 提供了一个从注册表中获取模型的命令,从而简化了获取本地开发和测试所需模型的过程。
- 列出可用模型 – Ollama 包含一个命令,用于列出注册表中的所有可用模型,从而提供其选项的清晰概述。这与 Docker 的图像列表功能相当。
- 运行模型 – 通过一个简单的命令,任何人都可以执行模型,从而在受控或实时环境中毫不费力地测试和评估模型的性能。
- 自定义和适应 – Ollama 更进一步,允许任何人修改和构建拉取的模型,类似于 Docker 创建和自定义映像的方式。此功能鼓励创新和通过快速工程定制模型。还可以将模型推送到注册表。
- 易用性 – 通过模仿 Docker 的命令行操作,Ollama 降低了入门门槛,使开始使用机器学习模型变得直观。
- 存储库管理 – 与 Docker 的存储库管理一样,Ollama 确保模型井井有条且可访问,从而营造出共享和改进机器学习模型的协作环境。
Ollama 运行时
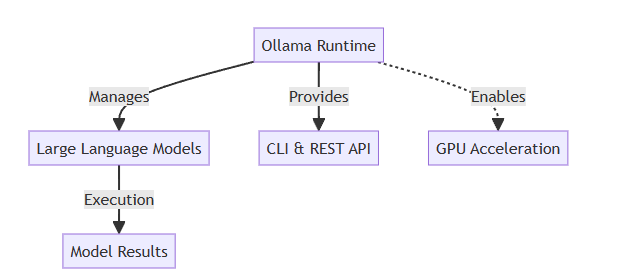
Ollama 提供了一个在本地管理模型的运行时。它提供了一个 CLI & REST API,作为用户或系统与运行时交互的接口,并由此扩展为大型语言模型。运行时启用 GPU 加速,这将显着加快模型的计算和执行速度。模型结果(即从运行模型中获得的输出或见解)由最终用户或其他系统使用。
快速开始
Linux 部署
Linux 系统部署提供了一键安装命令:curl https://ollama.ai/install.sh | sh
直接执行上述命令,可以完成默认安装,默认安装仅以 CPU 方式运行。
安装 CUDA 驱动程序(适用于 Nvidia GPU)
- 安装 Nvidia 容器工具包。
- 通过运行以下命令验证驱动程序是否已安装,该命令应打印有关 GPU 的详细信息:
nvidia-smi
Docker 部署
仅限 CPU
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama英伟达 GPU
- 安装 Nvidia 容器工具包。
- 在 Docker 容器中运行 Ollama:
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama运行模型
将 Ollama 作为命令行运行
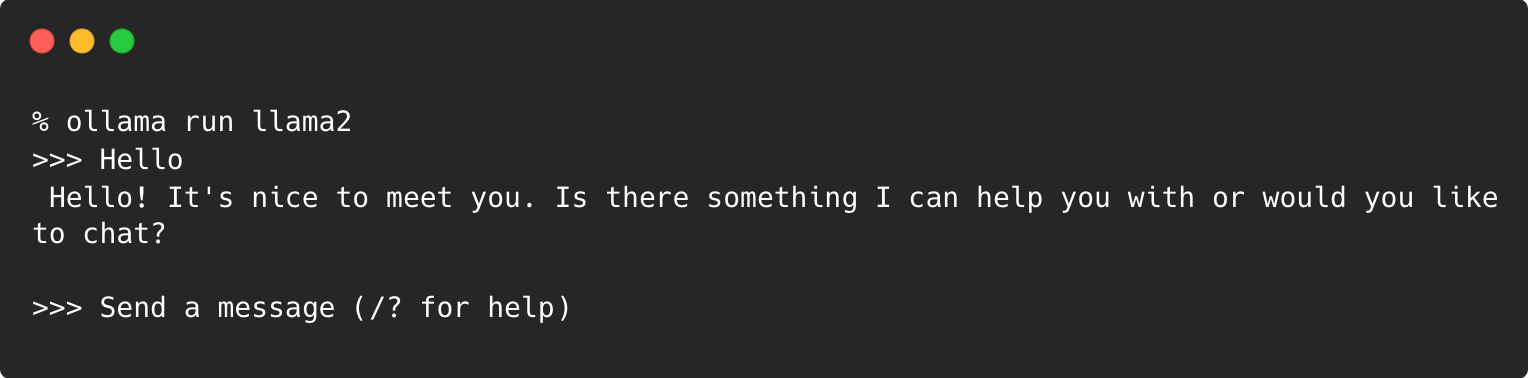
安装 Ollama 后,您可以在终端中使用以下命令运行所需的模型:
ollama run llama2然后,您可以开始向本地运行的模型发起提问了
将 Ollama 作为服务器运行
Ollama 也可以作为服务器运行。它有一个用于运行和管理模型的 API。您可以使用以下命令将 Ollama 作为服务器启动:
ollama serve此命令将在端口 11434 上启动 Ollama 服务器:

接下来,您可以使用例如 PostMan ,CURL 等任何客户端调用 REST API,下面是一个使用 CURL 的示例:’
如果您是使用 Docker 进行部署,您可以在容器中运行 Llama 2 这样的模型,然后可以选择使用 REST API 进行调用。
docker exec -it ollama ollama run llama2支持的模型
Ollama 支持 ollama.com/library 上提供的一系列模型,更多模型可以在 Ollama 库中找到。
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 2 | 7B | 3.8GB | ollama run llama2 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Dolphin Phi | 2.7B | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 2.7B | 1.7GB | ollama run phi |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| Vicuna | 7B | 3.8GB | ollama run vicuna |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
注意:您应该至少保留 8 GB 可用 运行内存 来运行 7B 型号,16 GB 来运行 13B 型号,32 GB 来运行 33B 型号。
结束
Ollama 提供了一种更易于访问和用户友好的方法来试验大型语言模型。无论您是经验丰富的开发人员还是刚刚起步,Ollama 都能提供工具和平台,让您深入了解大型语言模型的世界。
参考:
- https://ollama.com/blog/ollama-is-now-available-as-an-official-docker-image
- https://github.com/ollama/ollama
- https://github.com/ollama/ollama/blob/main/docs/linux.md
原创文章,作者:geeklinux.cn,如若转载,请注明出处:https://www.geeklinux.cn/jsjc/1389.html